Replicate Version control for machine learning
Lightweight, open source
01 Track experiments
Automatically track code, hyperparameters, training data, weights, metrics, Python dependencies — everything.
02 Go back in time
Get back the code and weights from any checkpoint if you need to replicate your results or commit to Git after the fact.
03 Version your models
Model weights are stored on your own Amazon S3 or Google Cloud bucket, so it’s really easy to feed them into production systems.
04 How it works
Just add two lines of code. You don’t need to change how you work.
Replicate is a Python library that uploads files and metadata (like hyperparameters) to Amazon S3 or Google Cloud Storage.
You can get the data back out using the command-line interface or a notebook.
import torchimport replicatedef train():# Save training code and hyperparametersexperiment = replicate.init(path=".", params={...})model = Model()for epoch in range(num_epochs):# ...torch.save(model, "model.pth")# Save model weights and metricsexperiment.checkpoint(path="model.pth", metrics={...})
05 Open source & community-built
We’re trying to pull together the ML community so we can build this foundational piece of technology together. Learn more.
06 You’re in control of your data
All the data is stored on your own Amazon S3 or Google Cloud Storage as plain old files. There’s no server to run. Learn more.
07 Works with everything
Tensorflow, PyTorch, scikit-learn, XGBoost, you name it. It’s just saving files and dictionaries – export however you want.
Throw away your spreadsheet
Your experiments are all in one place, with filter and sort. Because the data’s stored on S3, you can even see experiments that were run on other machines.
$ replicate ls --filter "val_loss<0.2"EXPERIMENT HOST STATUS BEST CHECKPOINTe510303 10.52.2.23 stopped 49668cb (val_loss=0.1484)9e97e07 10.52.7.11 running 41f0c60 (val_loss=0.1989)
Analyze in a notebook
Don’t like the CLI? No problem. You can retrieve, analyze, and plot your results from within a notebook. Think of it like a programmable Tensorboard. Learn more.
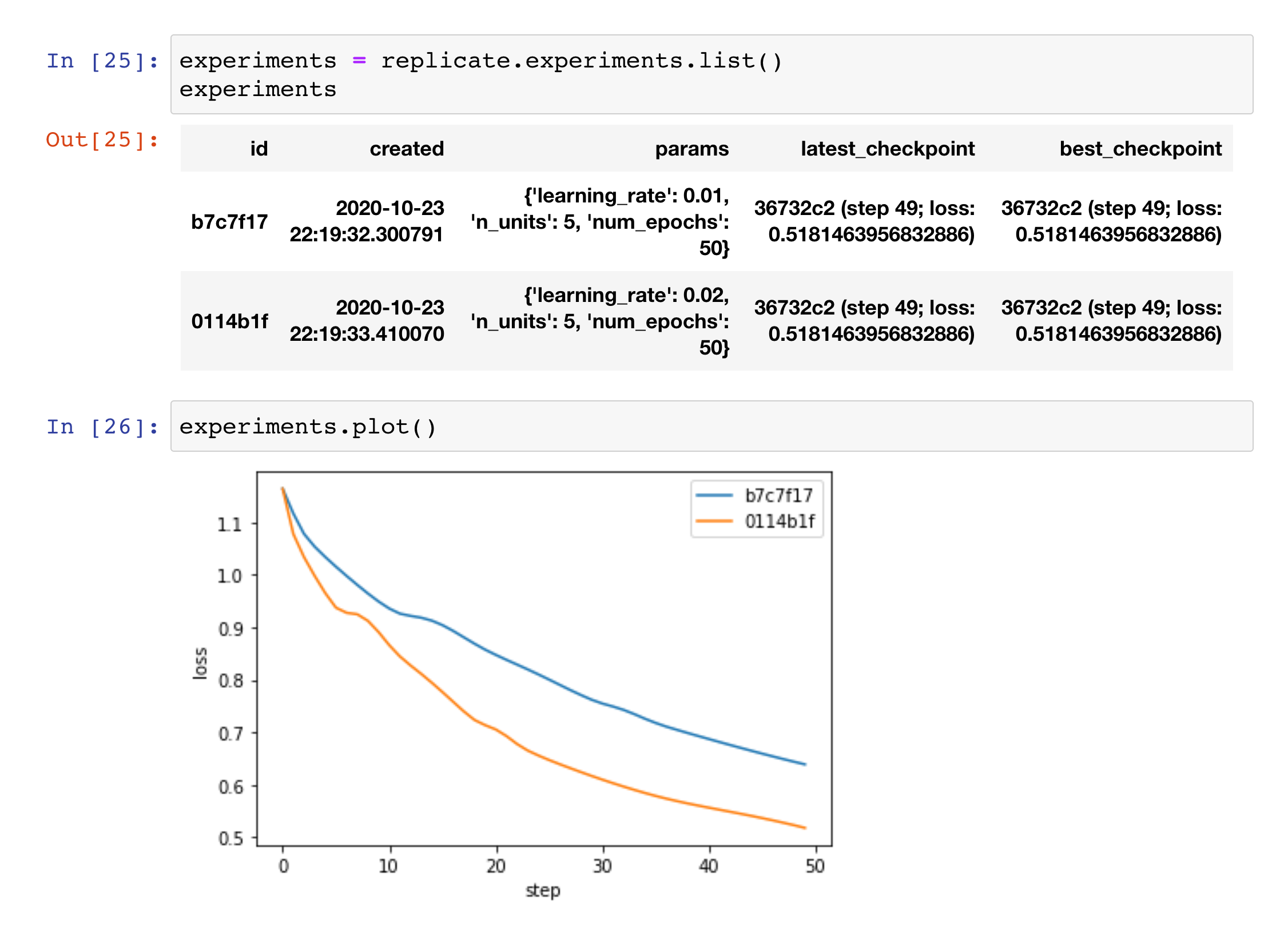
Compare experiments
It diffs everything, all the way down to versions of dependencies, just in case that latest Tensorflow version did something weird.
$ replicate diff 49668cb 41f0c60Checkpoint: 49668cb 41f0c60Experiment: e510303 9e97e07Paramslearning_rate: 0.001 0.002Python Packagestensorflow: 2.3.0 2.3.1Metricstrain_loss: 0.4626 0.8155train_accuracy: 0.7909 0.7254val_loss: 0.1484 0.1989val_accuracy: 0.9607 0.9411
Commit to Git, after the fact
If you eventually want to store your code on Git, there’s no need to commit everything as you go. Replicate lets you get back to any point you called experiment.checkpoint() so, you can commit to Git once you’ve found something that works.
$ replicate checkout f81069dCopying code and weights to working directory...# save the code to git$ git commit -am "Use hinge loss"
Load models in production
You can use Replicate to feed your models into production systems. Connect them back to how they were trained, who trained them, and what their metrics were. Learn more.

A platform to build upon
Replicate is intentionally lightweight and doesn’t try to do too much. Instead, we give you Python and command-line APIs so you can integrate it with your own tools and workflow.